Modern Knowledgebases
A few weeks ago, I migrated a dataset of around 30 million rows from MySQL to Parquet + DuckDB.
The query time dropped from nearly a minute to just a few seconds.
That shift changed how I thought about data: sometimes, the biggest gains come not from more compute,
but from how data is organized and read.
That realization made me curious — if columnar databases redefined analytics,
what’s the equivalent shift happening in knowledge systems?
Over the past year, I’ve been exploring how new systems—vector databases, embedding models, and retrieval frameworks—are quietly rebuilding the foundation of how machines represent and reason over information.
This post is my attempt to organize that understanding.
1. The Architecture of Modern Knowledgebases
At a high level, every modern “AI knowledgebase” sits on a stack of layers.
Each one has a distinct responsibility—from raw storage to semantic reasoning.
| Layer | Responsibility | Focus Area | Analogy |
|---|---|---|---|
| L0 – Physical Storage | Where the bytes actually live: disk, SSD, S3, or block storage. | Durability, throughput, cost. | The warehouse floor — where everything physically sits. |
| L1 – Data Layout | How vectors and metadata are serialized or chunked on disk. | Data formats, compression, compaction. | The shelving system — how boxes are arranged. |
| L2 – Indexing & Retrieval | How we find similar vectors quickly, without scanning everything. | ANN algorithms like HNSW, IVF, PQ, DiskANN. | The map of aisles — guiding you to the right shelf. |
| L3 – Search & API Layer | The database interface: how you insert, query, and filter. | Schema design, access control, hybrid filters. | The reception desk — turns requests into lookups. |
| L4 – Integration / Retrieval Orchestration | Coordinates ingestion, embeddings, hybrid search, and reranking. | Connectors, embedding pipelines, rerankers, query rewriting. | The librarian — knows where to look and stacks the right boxes for you. |
| L5 – Reasoning / Generation | The layer that actually “thinks.” Uses context from L4 and responds in language. | Prompting, planning, grounding, LLM reasoning. | The subject-matter expert — reads the boxes and explains. |
Notes:
- Vector stores (L0–L3) handle how knowledge is stored, indexed, and retrieved efficiently.
- Integration layers (L4) orchestrate embeddings, rerankers, and retrieval pipelines.
- Reasoning layers (L5) use that context to generate insights, answers, or summaries.
- Weaviate extends into L4; Kendra is a managed retrieval system; LangChain and LlamaIndex span both retrieval and reasoning.
- Together, these layers define the architecture of a modern AI knowledgebase — a system that doesn’t just store information, but can understand and communicate it.
2. Vectors and Meaning
At the heart of this new architecture is the vector — a numerical representation of meaning.
For example:
"The cat sits on the mat" → [0.12, -0.45, 0.88, ...] # 1536-dimensional embedding
A vector is just a long list of floating-point numbers, but its geometry captures relationships:
sentences or images that “mean” similar things are close together in this high-dimensional space.
Different models produce different kinds of embeddings, depending on what they were trained for.
| Model | Training Focus | Strengths |
|---|---|---|
| OpenAI text-embedding-3-large | General-purpose text | Broad coverage and strong multilingual performance. |
| AWS Titan Embeddings G1 | Enterprise documents | Handles structured, factual content effectively. |
| Cohere Embed v3 | Multi-domain semantic search | Tunable for classification and retrieval tasks. |
| CLIP (OpenAI) | Image ↔ text alignment | Bridges visual and language representations. |
| E5 (Microsoft) | Sentence-level retrieval | Optimized for semantic search and ranking. |
| Instructor XL | Task-specific embeddings | Performs well in RAG and domain-tuned workflows. |
Understanding embeddings is the first step.
But storing and searching through millions of them efficiently is what brought about vector databases.
3. Vector Databases: How They Differ
Not all vector stores are built the same way.
Some focus on scalability, others on analytics or simplicity.
Each can be understood through the same layered lens used above.
| System | Implements | Indexing (L2) | Storage Layout (L1) | Physical Storage (L0) | Summary |
|---|---|---|---|---|---|
| Weaviate | L3–L0 (+ optional L4 modules) | HNSW / DiskANN | Custom KV schema | Disk + S3 backup | A full-featured vector database with built-in hybrid search and RAG extensions. |
| LanceDB | L3–L0 | IVF_FLAT / PQ (Arrow-native) | Apache Arrow / Lance | Local / S3 | Columnar and analytics-friendly, ideal for local or hybrid workloads. |
| ChromaDB | L3–L0 | FAISS / HNSW | DuckDB / SQLite | Local | Lightweight and Python-first — great for experimentation and rapid prototyping. |
| S3 Vector Bucket | L3–L0 (managed) | AWS-managed ANN | Proprietary format | S3 | Serverless and fully managed; indexing and scaling handled by AWS. |
| OpenSearch (KNN Plugin) | L3–L0 (Lucene-based) | HNSW / IVF / PQ | Lucene segments | Disk / EBS | Text-first search engine with added vector retrieval capabilities. |
Common indexing methods:
- HNSW – graph-based, high recall with good latency.
- DiskANN – optimized for billion-scale datasets on disk.
- IVF_FLAT / IVF_PQ – cluster-based approaches balancing memory and speed.
- FAISS – a foundational library for many open-source vector stores.
- AWS-managed ANN – a proprietary, abstracted approach used in serverless systems.
4. From Storage to Understanding
Once the data is stored and indexed, the next challenge is orchestration — how to retrieve and reason over it.
| System | L0 | L1 | L2 | L3 | L4 | L5 | Notes |
|---|---|---|---|---|---|---|---|
| Weaviate | ✅ | ✅ | ✅ | ✅ | ✅ (auto-embed, hybrid, rerank, “generative” plugins) | ❌ | Has optional L4 modules but relies on external LLMs for reasoning. |
| Pinecone | ✅ | ✅ | ✅ | ✅ | ❌ | ❌ | Pure vector database; bring your own orchestration and reasoning layers. |
| LanceDB | ✅ | ✅ | ✅ | ✅ | Minimal | ❌ | Focused on analytics; orchestration handled externally. |
| ChromaDB | ✅ | ✅ | ✅ | ✅ | Light | ❌ | Great for quick RAG prototypes via LangChain or LlamaIndex. |
| OpenSearch (KNN) | ✅ | ✅ | ✅ | ✅ | Hybrid keyword + vector | ❌ | Adds ANN to a text-based search engine. |
| Amazon Kendra | Managed | Managed | Managed | Managed | ✅ | ❌* | A managed retrieval system; for generation, pair with Bedrock or another LLM. |
| LangChain | ❌ | ❌ | ❌ | ❌ | ✅ | ✅ | Framework that orchestrates retrieval (L4) and reasoning (L5) across data sources. |
| LlamaIndex | ❌ | ❌ | ❌ | ❌ | ✅ | ✅ | Similar to LangChain; adds graph-based indexing and composability. |
| Bedrock / OpenAI / Claude / Gemini | ❌ | ❌ | ❌ | ❌ | ❌ | ✅ | Pure reasoning layer — uses retrieved context to generate answers. |
“Managed” means the internal indexing and storage details are not visible to the user.
5. E2E Flow
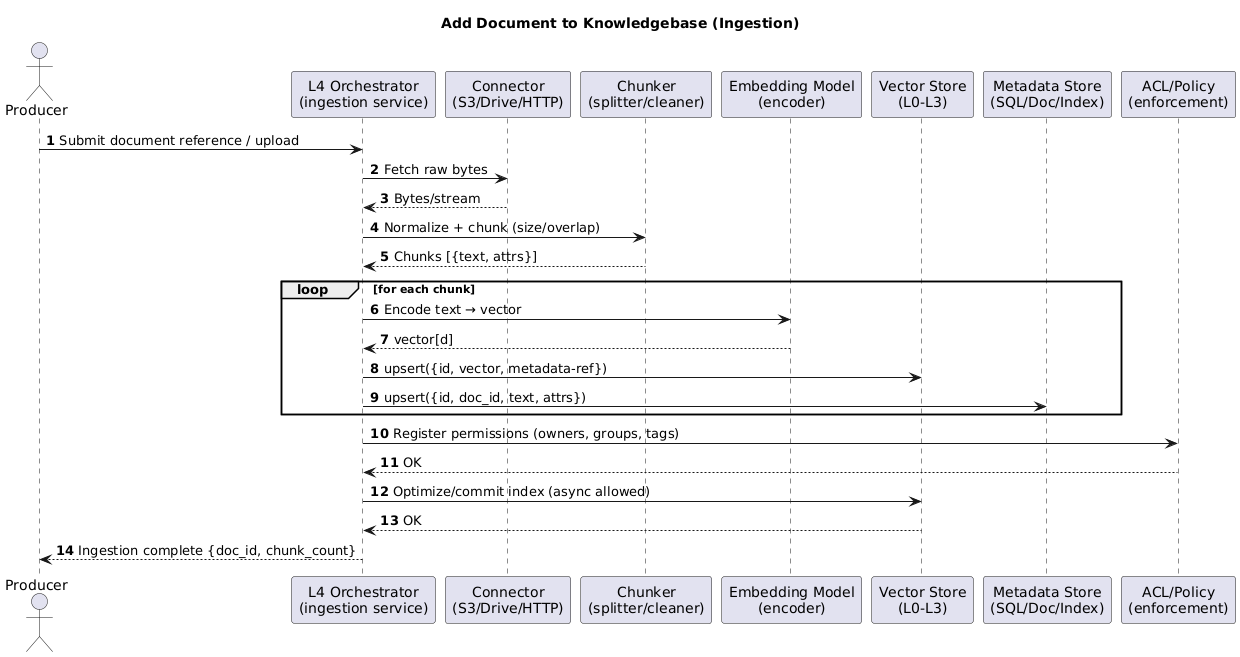
Ingestion Pipeline
- Vector Store (L0–L3) handles the upserts and index commits.
- L4 performs connectors, chunking, embedding, and ACL registration.
- Metadata goes to a metadata store for filters, facets, and citations.
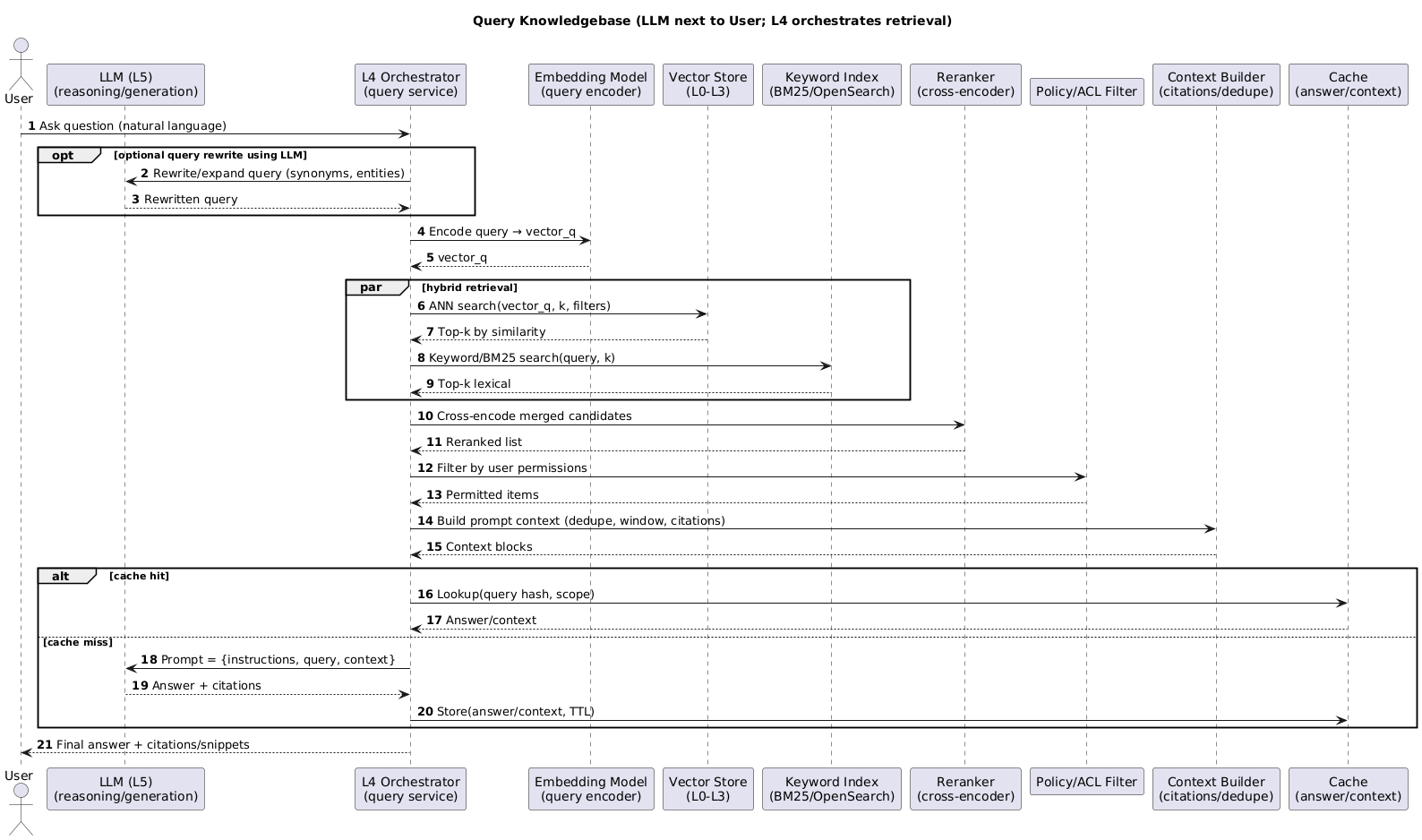
Query the knowledgebase (retrieval orchestration + LLM)
In this sequence, the LLM (L5) is drawn directly beside the User because it’s the layer the user interacts with — the conversational or reasoning interface.
Conceptually, however, L5 depends on L4: the orchestrator (L4) handles retrieval, embeddings, reranking, filtering, and context assembly before the LLM can reason over it.
In other words, L4 prepares the knowledge, and L5 expresses it. The Vector Store (L0–L3) remains purely a retrieval substrate — it stores, indexes, and returns vectors, but performs no reasoning or synthesis.