1. Foundation Models vs LLMs
Foundation models are massive neural networks trained on diverse data (text, code, audio, video, images) so they can be adapted to many downstream tasks. Large Language Models (LLMs) are a subset focused on token-based language tasks. Use the matrix below for quick exam recall.
| Dimension | Foundation Model | Large Language Model (LLM) |
|---|---|---|
| Scope | Multi-modal (text, audio, image, video, code) or unimodal | Primarily language + code; some add image adapters |
| Training Task | Generic self-supervised objectives (masking, contrastive learning, etc.) | Autoregressive next-token prediction |
| Input / Output | Any supported modality, embeddings, or metadata | Tokens (text/code) with optional tool-calls |
| Adaptation | Task-specific fine-tuning, adapters, RLHF | Prompting, instruction tuning, RLHF, guardrails |
| Use Cases | Vision, audio, multi-modal search, robotics | Chatbots, Q&A, summarization, agents, code-gen |
2. Training Hyperparameters You Must Know
- Epochs – One pass over the full training set. Multiple batches make up an epoch; models iterate through many epochs until accuracy converges or validation loss stops improving.
- Batch size – Number of records processed per update. Small batches fit on modest GPUs and introduce more gradient noise (helpful for generalization); large batches use more memory but stabilize training.
- Learning rate – Size of each weight update. High rates (e.g.,
1e-1) converge quickly but can overshoot; low rates (e.g.,5e-5for BERT) are slower but safer. Most schedulers decay the rate as training progresses.
Remember: adjusting these three knobs is often enough to fix unstable training before you consider changing the model architecture.
3. Why Transformers Matter
Transformers replaced recurrent networks by relying on self-attention, which lets every token weigh every other token in the sequence to build contextual embeddings. Positional encodings preserve word order, and encoder/decoder stacks process inputs in parallel so latency scales well on GPUs. This architecture powers modern translation, summarization, speech, and vision-language models—and is the backbone of Bedrock and SageMaker JumpStart offerings.
4. Steering LLM Output
- Temperature (0–1) – Scales the probability distribution before sampling. Lower values push the model toward the single most likely answer (deterministic); higher values encourage creative or varied text.
- Top-p (nucleus sampling) – Keeps only the smallest set of tokens whose cumulative probability is ≥
p. Lowerplimits the candidate pool to highly probable tokens; higherpallows adventurous replies. Amazon Bedrock exposes both parameters for every supported model.
Exam tip: Control hallucinations by lowering temperature/top-p and grounding answers with retrieved context.
Prompt Engineering
- Zero-shot – instruction only; rely on the model’s pre-training.
- Few-shot – add exemplars so the model mimics the pattern.
- Chain-of-thought – ask for step-by-step reasoning to surface intermediate logic.
- Few-shot + CoT – provide worked examples with reasoning, then request the same structure for the new task.
- RAG – retrieve fresh/internal data and inject it into the prompt; complements prompt style by adding knowledge.
- Prompt structure checklist – instruction, context, constraints, output format. Validation happens afterward, not inside the prompt.
- Use cases – chocatalogue2025!ose prompting tweaks for reasoning changes; choose RAG when knowledge gaps exist.
5. Retrieval-Augmented Generation (RAG)
RAG keeps foundation models up to date without re-training:
- Ingest documents (PDFs, FAQs, catalogs) and chunk them with metadata.
- Create embeddings and store them in a vector index such as OpenSearch Serverless, Aurora Postgres + pgvector, or Knowledge Bases for Amazon Bedrock.
- When the user asks a question, retrieve the most relevant chunks.
- Pass the question + retrieved context to the LLM so the answer cites fresh data.
This pattern is cheaper than fine-tuning every time the knowledge base changes and is the default recommendation on the exam for “most current answers at low cost.”
Exam tip: Always justify RAG when the requirement is “fresh data without retraining.”
Responsible AI and Governance
- Enforce data validation/cleansing pipelines before training or inference to reduce bias and drift.
- Maintain written data quality standards as core AI governance controls.
- Responsible AI pillars: fairness, explainability, privacy, robustness, safety, accountability.
- Apply guardrails/admin controls (e.g., Bedrock guardrails, Amazon Q Business policies) to suppress sensitive or off-topic outputs.
Security and Compliance
- Layered controls – access policies (IAM, VPC), data protection (encryption, redaction), detailed logging, and compliance evidence.
- Data logging – record prompts, model invocations, and decisions for monitoring, troubleshooting, and audits.
- AWS Artifact – self-service access to AWS SOC, ISO, and PCI reports when proving compliance.
- Highlight logging + Artifact in exam answers that mention regulators, internal audits, or shared responsibility clarifications.
6. Specializing a Foundation Model
6.1 Domain Adaptation Fine-Tuning
- Start with a general foundation model, then fine-tune on labeled domain-specific prompts/responses.
- Best when you have curated task data (support tickets, contracts, medical summaries) and need the model to follow strict formats or voice.
- Requires fewer tokens than pre-training because you are only nudging existing weights.
6.2 Continued Pre-Training
- Feed the model a large unlabeled corpus from your domain to extend its vocabulary and context understanding before supervised fine-tuning.
- Use this when jargon-heavy data (legal, biotech, oil & gas) is missing from the public corpus. You still need to run a fine-tune afterward for task instructions.
Exam tip: choose fine-tuning for adapting behavior on known tasks; choose continued pre-training when the base knowledge is insufficient.
Evaluation Metrics
- Efficiency – latency, throughput, or cost-per-token; use when speed/cost limits exist.
- Task metrics – accuracy, F1, BLEU, ROUGE for technical fit-for-purpose checks.
- Business/operational metrics – ARPU, CSAT, deflection; expect exam questions to mix technical and business KPIs to ensure you map each requirement to the correct metric type.
- Remember: ARPU is a business KPI, not a model performance metric.
Agents and Real-Time Augmentation
- AI agents connect model reasoning to tools, APIs, workflows, and databases to execute tasks.
- Typical flow: parse natural language intent → map to tool or API call → send results back through the model for explanation.
- Use retrieval or tool calls when real-time or transactional data is required; prompting alone cannot access live systems.
- Bedrock Agents or custom orchestration can translate user input into API/SQL calls, keeping humans in the loop for approvals.
7. Embeddings and BERT
Embedding models convert words, sentences, or images into dense vectors so that similar items land close together in multi-dimensional space. BERT (Bidirectional Encoder Representations from Transformers) generates contextual embeddings by looking at words both before and after the target token. Because embeddings change with context, BERT excels at intent detection, entity recognition, and semantic search where static word vectors fail.
8. AWS Service Map
- Amazon Bedrock – managed foundation-model access for generative apps without training from scratch.
- Amazon SageMaker – custom ML build/train/tune/deploy lifecycle.
- Amazon Lex – conversational interface builder using intents and slots.
- Amazon Kendra – enterprise search with intelligent retrieval over connected document stores.
- Amazon Q Business – managed enterprise AI assistant with connectors, RBAC, and admin guardrails.
- Amazon Comprehend – NLP service for sentiment, key phrases, classification, and entity extraction.
| Service | Category | What to Remember |
|---|---|---|
| Amazon Bedrock | Foundation Models | Serverless access to Titan, Anthropic, Meta, Cohere, Mistral models; built-in RAG and guardrails. |
| Amazon SageMaker | Build/Train/Deploy | Custom training, fine-tuning, autopilot, and JumpStart model zoo. |
| Amazon Transcribe | Speech-to-Text | Streaming/batch transcription with channel identification and redaction. |
| Amazon Comprehend | Natural Language | Entity detection, sentiment, key phrases, PII redaction; supports custom classification. |
| Amazon Kendra | Enterprise Search | High-accuracy semantic search with connectors, relevance tuning, and FAQs. |
| Amazon Rekognition | Vision | Image/video labels, face search, unsafe content, text detection. |
| Amazon Textract | Document AI | Structured extraction (forms, tables) beyond OCR. |
| Amazon Polly | Text-to-Speech | Neural voices, Speech Marks for lip-sync, Lex integration. |
| Amazon Lex | Conversational | Build chat/voice bots with slots, Lambda fulfillment, multi-lingual support. |
| Amazon Q Business | Enterprise AI Assistant | Managed assistants with connectors, RBAC, guardrails, and analytics. |
| Amazon Translate | Machine Translation | Real-time and batch translation with active custom terminology. |
Exam tip: Know the basic capability of each managed AI service—questions often ask you to swap Rekognition (vision) vs Textract (document parsing) vs Comprehend (text NLP).
Exam Traps
- Prompt validation is post-processing; exam answers that list it as a core prompt element are wrong.
- ARPU belongs to business KPI dashboards, not ML evaluation tables.
- RAG adds knowledge; prompt tweaks only change reasoning style—never claim prompting alone provides fresh data.
Memory Hooks
- Bedrock = FM platform
- SageMaker = custom ML platform
- Lex = chatbot flow
- Kendra = retrieval/search
- Comprehend = NLP extraction
- Amazon Q Business = enterprise AI assistant
- RAG = retrieve then generate
- Agents = LLM + tools/API bridges
- Efficiency metric = latency/cost focus
- Data logging = audit trail
9. LLM Conversation Flow Diagram
Use this UML snippet to visualize how user prompts move through retrieval, inference, and back to the UI.
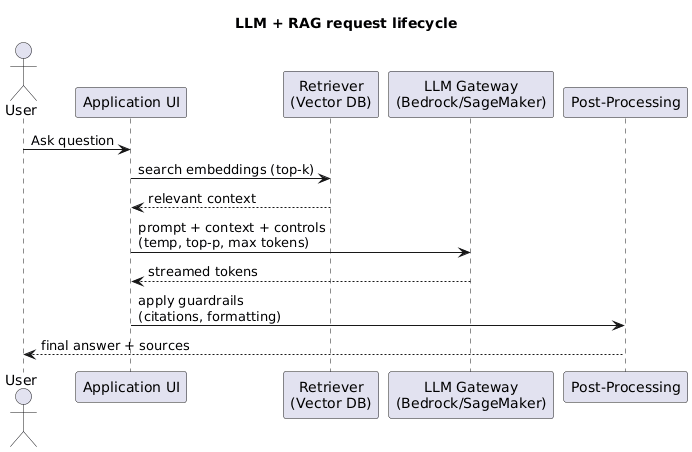
9. Prompt Engineering Essentials
- Zero-shot vs few-shot – Zero-shot relies purely on instructions, ideal for broad Q&A; few-shot includes curated examples so the model mirrors tone or schema. Prefer few-shot when responses must follow strict formatting.
- System vs user prompts – System prompts set persona/policies; user prompts keep transient context. Adjust system prompts for compliance tone without retraining.
- Structured outputs – Describe the schema (JSON/YAML) and list mandatory/optional fields; combine with Bedrock Guardrails or Lex slot validation to reject malformed payloads.
- Decoding controls – Temperature, top-p, max tokens, and stop sequences govern creativity, latency, and runaway responses. Exams often ask you to lower temperature and add stop sequences to cap emails or policies.
- Tool/function calling – Document available functions (name + parameters). The LLM decides whether to call a tool and returns JSON so the orchestrator can act. Key concept for Bedrock Agents and custom controllers.
Exam tip: Keep prompts short, move reusable policy text to templates, and cap max_tokens to avoid surprise billing.
10. RAG Architecture & Tuning
- Chunking + overlap – Target 200–500 token chunks with 10–20% overlap so passages maintain context without blowing up storage.
- Embeddings + vector stores – Use Titan Text Embeddings, Cohere Embed, or open-source (bge/e5) with OpenSearch Serverless, Aurora pgvector, Neptune Analytics, or Bedrock Knowledge Bases.
- Top-k retrieval + metadata filters – Start with
k=3–5, then filter by product, locale, or classification labels to cut noise. - Reranking + hybrid search – Combine dense vectors with keyword/BM25 or use rerankers when rare terms or legal phrases matter.
- Latency vs cost – Larger vectors improve recall but add milliseconds and storage fees. Cache popular context windows; pre-compute embeddings offline.
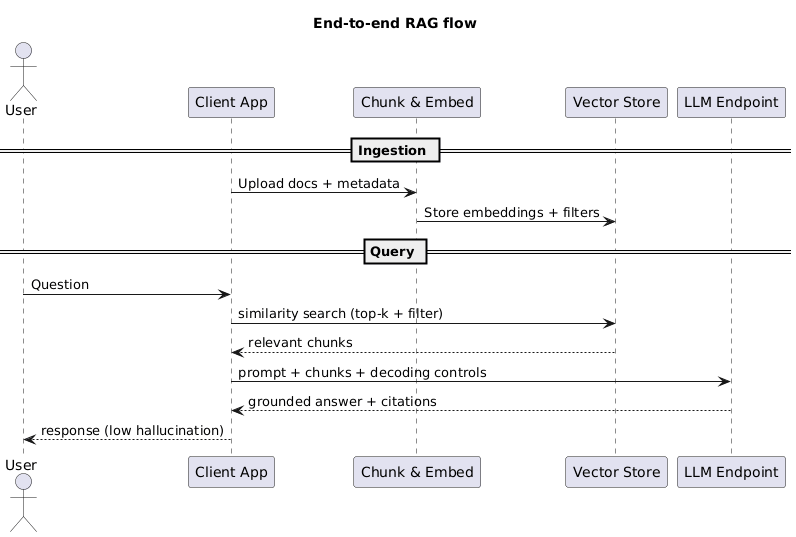
Exam tip: Answer “Use Bedrock Knowledge Bases” whenever the question stresses managed ingestion + retrieval.
11. Agents & Tool Use
- Agent vs RAG – Use RAG for better context inside a single response. Use agents when you need planning, multi-step workflows, or to call APIs/DBs dynamically.
- Tool calling patterns – The agent interprets intent, chooses a tool (Lambda/HTTPS/Step Functions), executes it, ingests the result, and may loop until complete.
- AWS mapping – Bedrock Agents orchestrate reasoning, call Lambda for business logic, Step Functions for long-running jobs, and can integrate RAG for grounding.
This diagram is worth keeping because it clarifies a common point of confusion: the agent is the controller/orchestrator, the model is the reasoning engine, tools perform actions, state holds short-term working memory, and the vector DB acts as a retrieval index for long-term knowledge.
Concrete example: in a coding assistant, a user asks to fix a login bug, the model suggests inspecting auth.py, the agent reads the file with a tool, stores the result in state, optionally retrieves related docs from the vector index, and then calls the model again with the updated context.

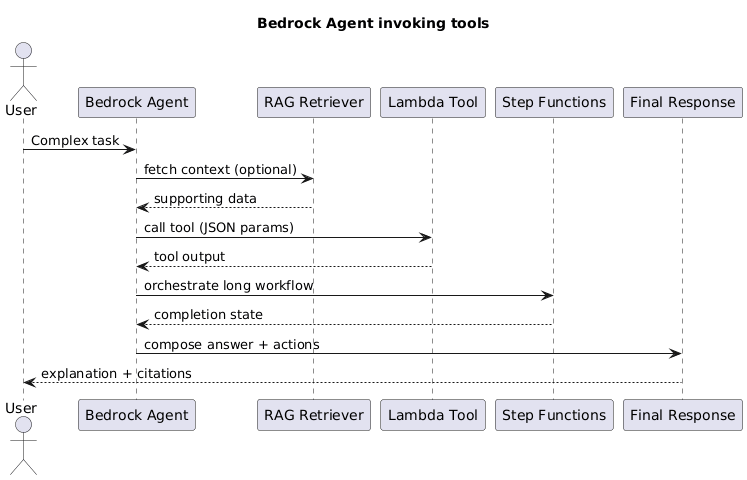
Exam tip: If the requirement says “call internal APIs and external SaaS with reasoning,” pick Bedrock Agents with Lambda tools.
12. Evaluation & Hallucination Control
- Offline evaluation – Score prompts/models against golden datasets for accuracy, BLEU/ROUGE, or custom rubric. Automate in SageMaker pipelines.
- Human + LLM-as-judge – SMEs validate edge cases; LLM judges accelerate regression testing but must be calibrated.
- Grounding + citations – Return snippet IDs or URLs so auditors can verify answers. Bedrock Knowledge Bases can include citations automatically.
- Temperature + guardrails – Keep temperature/top-p low for factual tasks and add Guardrails for profanity/PII filters or JSON schemas.
Exam tip: When compliance reviewers are mentioned, respond with “human-in-the-loop evaluation plus logged citations.”
13. Responsible AI, Privacy, Security
- Bias/fairness – Audit datasets, compare outputs across demographic slices, and document mitigations.
- PII governance – Mask prompts, encrypt data (KMS), route calls through VPC endpoints/PrivateLink, and restrict IAM roles for agents/tools.
- Hallucination + safety – Pair RAG grounding with Guardrails to block unsafe content and require human review for high-risk actions.
- AWS mapping – Use Bedrock Guardrails, IAM least privilege, CloudTrail logging, and encrypted vector stores/S3 buckets.
14. Cost Optimization for GenAI
- Token drivers – Shorten system prompts, trim few-shot examples, and cap max tokens. Every unused token is direct cost.
- Caching – Cache embeddings, retrieval hits, and deterministic responses to avoid re-querying the LLM.
- Model sizing – Start with smaller models (e.g., 13B) and scale up only if KPIs demand it. Use distillation or parameter-efficient fine-tuning for narrow tasks.
- Batch vs real-time – Batch summarize archives or compliance logs; reserve real-time endpoints for interactive needs. SageMaker and Bedrock both support asynchronous invocations.
- RAG vs fine-tune vs prompt – RAG minimizes retraining when knowledge updates frequently, fine-tuning lowers per-request tokens for repetitive tasks, and improved prompting can defer expensive training entirely.
Exam tip: Mention “use Bedrock serverless invocation + caching” whenever the question references “spiky demand” or “cost control.”
15. Decision Matrix
| Approach | When to Choose | Exam Trigger Words |
|---|---|---|
| Prompting | General knowledge, low customization, rapid experimentation. | “No training budget,” “quick prototype.” |
| RAG | Fresh proprietary data, citations, large document sets. | “Latest manuals,” “ground answers,” “no retraining.” |
| Fine-tuning | Strict formats, domain tone, curated labeled data. | “Consistent summaries,” “approved style guide.” |
| Continued Pretraining | Missing vocabulary/jargon, massive unlabeled domain corpus. | “Industry-specific terms,” “expand base knowledge.” |
| Agents | Multi-step reasoning, tool invocation, integrations. | “Plan workflow,” “call APIs,” “take actions.” |